Introduction: Framing the Challenge
More than 95% of enterprise AI projects in 2025 will depend on real-time analytics to promote innovation, operational effectiveness, and customer engagement. Less than half of organizations report success in implementing AI that actually makes a difference, which is regrettably the case for many. The data pipeline is the missing element, not the model. Models never realize their full potential without a solid, trustworthy foundation.
This blog examines the architectures, pipelines, and pitfalls that form the three fundamental pillars of real-time AI and describes how Techmango’s Data Engineering Services are uniquely suited to help businesses navigate each stage. We demonstrate how our industry-standard method accelerates AI value while avoiding common pitfalls by fusing technical knowledge with useful deployment strategies.
Architectures: Laying the Foundation
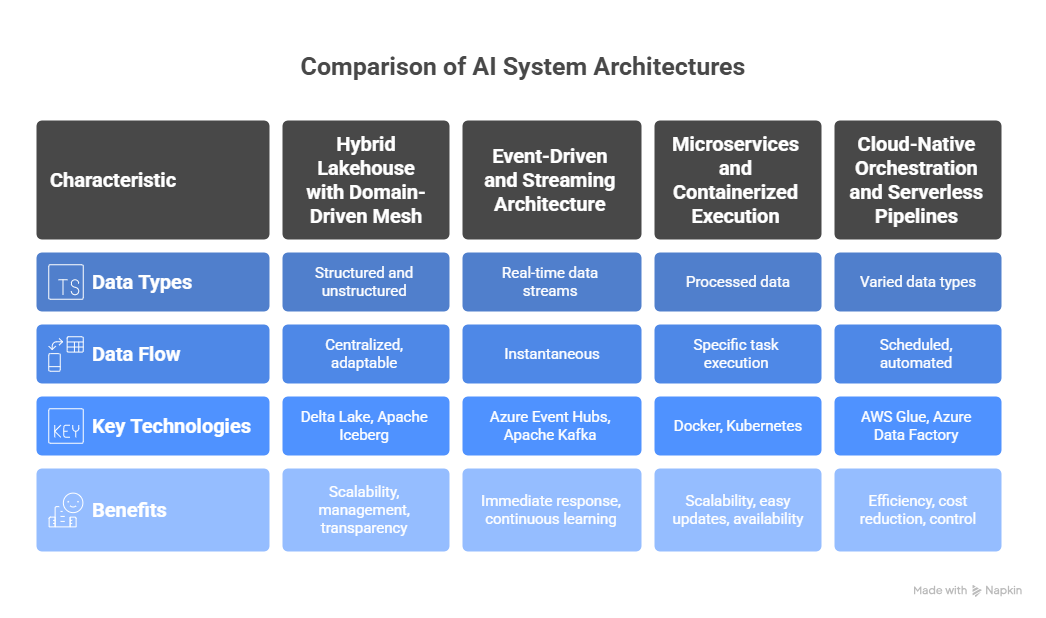
Hybrid Lakehouse with Domain-Driven Mesh
AI systems can handle unstructured data like logs, photos, and documents as well as structured data from databases. A lakehouse architecture supports both types of data. It blends the adaptability of a data lake with the efficiency of a conventional data warehouse.
AI systems can now access raw data and clean tables in a single environment thanks to this configuration. It facilitates advanced analytics and facilitates scaling and management.
This is furthered by a domain-driven mesh approach. Data pipelines, data structures, and quality controls are owned and operated by each team. This establishes a transparent system that distributes data ownership while adhering to corporate standards.
Table formats such as Delta Lake or Apache Iceberg help with version control and schema enforcement. These tools ensure that data is reliable, consistent, and ready to use across all teams.
Event-Driven and Streaming Architecture
Real-time AI depends on immediate data flow. Event-driven systems provide data instantly, eliminating the need to wait for hourly or daily batch jobs.
Real-time data collection and movement is facilitated by streaming platforms such as Azure Event Hubs, AWS Kinesis, and Apache Kafka. User clicks, financial transactions, app logs, and sensor readings from smart devices are a few examples of this.
Within seconds of being generated, new data enters a stream and is accessible to other systems. The data is subsequently picked up by processing engines for use in AI models or additional analysis.
This architecture facilitates immediate response and ongoing learning. Businesses can use it to stay informed, act quickly, and base decisions on the most recent data.
Microservices and Containerized Execution
Once the data arrives, it must be cleaned, transformed, and prepared before AI models can use it. This work is done using microservices.
Microservices are small and focused programs that each perform a specific task such as filtering, formatting, or enriching data. These services are packaged into containers using tools like Docker.
The containers are managed by platforms like Kubernetes or Amazon ECS. This allows businesses to scale each process separately, apply updates easily, and maintain high availability.
Different programming languages can be used depending on the task. This flexible setup ensures high performance and smooth operations.
Monitoring tools such as Prometheus help track system health, detect problems, and keep everything running efficiently.
Cloud-Native Orchestration and Serverless Pipelines
Careful coordination is necessary to manage the entire data workflow. From ingesting data to training AI models, each task needs to be completed in the proper sequence and at the appropriate time.
These workflows are managed with the aid of cloud-based platforms like AWS Glue and Azure Data Factory, or orchestration tools like Apache Airflow and Dagster. They plan tasks, keep tabs on dependencies, and assess advancement.
Serverless computing is a wise option for brief or minor tasks like file conversions or API calls. Services like Azure Functions and AWS Lambda manage scaling automatically and only execute code when necessary. Teams can operate more effectively when scheduled and serverless pipelines are combined. While keeping tight control over data processes, it lowers infrastructure costs and delays.
The first and most crucial step in creating real-time AI systems is developing a dependable architecture. Businesses can move data fast, process it precisely, and react instantly when it is properly designed with the help of professional data engineering services.
Contemporary data architectures make use of cloud orchestration for control, streaming tools for speed, lakehouse platforms for flexibility, and containers for processing. Businesses can build a solid data foundation that fosters AI development and long-term commercial success with the help of data engineering services.
Pipelines: Channels of Intelligence
Ingestion Pipelines: Moving Data from Source to System
In a real-time AI environment, data needs to flow smoothly from the source to processing systems. Ingestion pipelines make this possible.
Data enters the system through various sources such as REST APIs, change data capture (CDC) tools, Kafka clients, and direct connections. At the point of intake, data engineering services apply light enhancements like adding location data or adjusting time formats. The data is organized into topics, assigned to partitions, and storage settings are optimized to balance speed and efficiency.
These early steps ensure that the data keeps its full context without slowing down the pipeline.
Streaming Transformations and Enrichment
Once data is ingested, stream processing tools like Spark Streaming, Apache Flink, or AWS Lambda help transform it in real time.
These tools handle:
- Enrichment: Adding more context by looking up related information (such as user profiles).
- Cleansing: Checking the data against predefined formats to ensure quality.
- Feature Calculations: Creating rolling averages or encoding values needed for AI models.
We carefully monitor processing time, memory usage, and backup checkpoints to make sure the system is fast, reliable, and always available.
Batch and Analytics Pipelines
Not all data needs to be processed in real time. Some tasks are scheduled in batches to support broader analytics and historical tracking.
These pipelines manage:
- Periodic snapshots of incoming data for audits.
- Aggregated insights like daily user activity.
- Datasets used for retraining AI models.
Well-designed data engineering services use workflow tools like Airflow to create reusable tasks. These pipelines include clear metadata tracking, backup steps, and links to catalog systems for future reference and auditing.
Model Training and Serving Pipelines
AI models need clean, processed data to learn effectively and perform well. Dedicated pipelines support this training and deployment lifecycle.
These pipelines handle:
- Extracting features from batch data.
- Training models using tools like TensorFlow, PyTorch, or XGBoost.
- Storing model versions in platforms like MLflow.
- Deploying models as REST APIs or integrating them directly into real-time systems.
To ensure stability, inference services are packaged in Kubernetes pods and protected by tools like Istio or Envoy. These provide traffic control, logging, monitoring, and automatic scaling.
Observability and Governance Pipelines
Trust and compliance are essential when dealing with large-scale AI systems. Governance pipelines are built into the data stack to provide visibility and control.
These pipelines include:
- Schema validation to ensure data structure accuracy.
- Real-time metrics collected with tools like Prometheus or CloudWatch.
- Alerts for detecting unusual behavior.
- Data lineage tracking through tools like OpenLineage or Marquez.
- End-to-end tracing using Jaeger or Zipkin to follow data movement.
All this data integrates into enterprise dashboards so teams can track performance, detect issues early, and meet compliance standards.

Common Pitfalls in Real-Time AI Systems
1. High Latency Choke Points
Delays may result from manual procedures, batch pipelines, or low-speed brokers that move data slowly. A brief delay can result in missed opportunities or a bad user experience.
2. Schema Breaks and Data Drift
Changes in the format or structure of incoming data have the potential to disrupt downstream pipelines or produce inaccurate outcomes. These problems can cause silent data failures and are difficult to identify.
3. Overuse of Resources
Particularly when data flow is irregular, operating sizable compute clusters or maintaining processing jobs continuously can waste resources and result in needless cloud expenses.
4. Poor Data Governance
The system could become unreliable in the absence of appropriate data tracking, access controls, or sensitive field masking. Trust problems and compliance risks result from this.
5. Model Drift and Stale Features
If AI models are not updated, their accuracy gradually declines. Inaccurate forecasts and lost business value can result from using antiquated data or features.

Business Impact: Real-Time AI in Action
- Fraud detection: Transactions are scored in under 100ms, reducing false positives by 30%
- Retail personalization: Stream-based recs increase session conversion by 18%
- Manufacturing predictive maintenance: Sensor pipelines enable failure alerts 24 hours before breakdown, saving 3% in OEE
- Healthcare triage: Real-time vitals processing helps trigger alerts 2x faster than traditional systems
Each result emerges from stable data foundations—structured through layered pipelines managed and optimized by Techmango.
Techmango: Your Strategic Data Partner
Gold-Standard Solutions
Every element Techmango builds is governed, monitored, and aligned to domain models and performance SLAs. Our expertise enables businesses to extract insights reliably, at scale, fueled by real-time intelligence.
Consulting to Delivery
Our teams help you navigate across data maturity levels, from strategic assessments to implementation and optimization, guaranteeing that your real-time AI roadmap yields quantifiable return on investment.
Tech Portfolio
Proven with Kafka, Flink, Spark, Airflow, Kubernetes, Delta Lake, MLflow, Prometheus, Grafana, and enterprise-grade catalogs.
Global Delivery, Local Impact
We combine extensive domain and compliance knowledge with round-the-clock engineering execution in our offices in the USA, UAE, and delivery centers in India.
How We Engage: The Techmango Delivery Model
- Discovery & Assessment
Infrastructure audit, tool chain review, KPI alignment - Architecture Blueprint
Create a streaming layout and hybrid lakehouse that are specific to domains. - Pipeline Implementation
Create feature generation, batch DAGs, streaming ingestion, and inference endpoints. - Governance & Observability Integration
Create lineage exporting, RBAC flows, alerts, and metric dashboards.ing - Deployment & Optimization
Turn on cost analysis, security hardening, and autoscaling. - Continuous Iteration
Rollout of the new pipeline, real-time tuning, and model retrain cadence
Each step is measured via metrics—maximum latency, throughput, cost per terabyte, model accuracy, and adoption rate.
Client Testimonial
“Techmango modernized our real-time data ecosystem. They reduced decision latency to under 200ms with full governance baked in. Our AI models now drive real business value—not just reports.”
— CTO, Leading US Retail Firm
Call to Action
Strong data engineering is essential for real-time AI; it will not be an option. Techmango’s data engineering services can help your team overcome issues like high latency, brittle pipelines, or a lack of confidence in data.
Build scalable, compliant, and robust real-time data systems with Techmango to support AI and advance your company.
Get started on your strategic real-time data journey by getting in touch with us right now.





